요약
JPA는 객체지향 언어인 자바와 데이터베이스의 구조가 달라서 생기는 문제를 개발자가 더 쉽게 해결할 수 있도록 돕는다.
객체지향은 행동과 책임 중심으로 설계되고, 데이터베이스는 데이터 중심으로 설계된다.
객체지향은 참조의 방향이 정해져있지만, 데이터베이스는 하나의 외래키로 양쪽 모두 참조 가능하다.
동일성 비교를 객체는 인스턴스의 주소값으로 하고 데이터베이스는 기본키로 한다.
JPA는 이런 차이를 개발자가 신경쓰지 않게 해준다.
JPA는 반복적인 SQL 작성을 줄여준다.
반복적인 SQL 작성
JDBC API로 Member 객체를 저장하거나 조회해보자.
1 | public class MemberDao { |
Member 객체를 저장하는 데 정말 많은 코드가 많이 필요하다.
만약 테이블이 100개이면 저장하는 메서드 100개를 반복해서 만들어줘야 한다.
만약 데이터베이스를 컬렉션이라고 상상해보면 다음과 같지 않을까?
1 | members.add(member); |
JPA를 사용하면 컬렉션처럼 객체를 데이터베이스에 저장시킬 수 있다.
1 | entityManager.persist(member); |
JPA는 객체와 매핑 정보를 보고 적절한 SQL을 알아서 실행시킨다.
개발자는 반복적인 SQL 작성을 하지 않아도 된다.
상속 구조 구현 문제
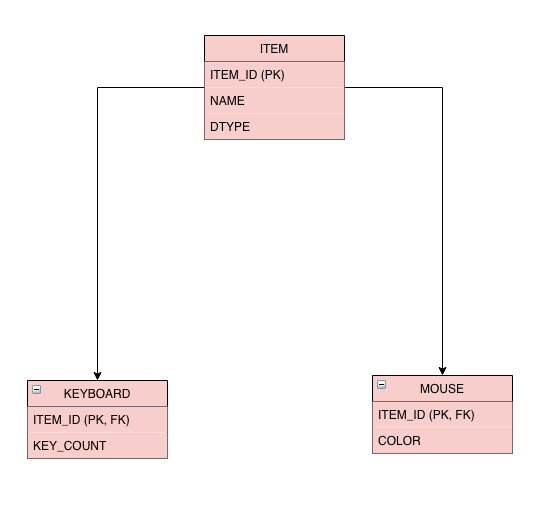
데이터베이스는 객체 지향 상속을 지원하지 않으니 위 그림처럼 DTYPE 칼럼을 추가해서 어떤 자식 테이블과 관계가 있는지 확인할 수 있어야 한다.
문제는 이런 경우 개발자가 Keyboard 객체를 저장하려면
- ITEM 테이블에 insert 하는 쿼리
- KEYBOARD 테이블에 insert 하는 쿼리
두 개의 쿼리를 작성해야 한다.
데이터베이스에서 객체를 가져올 때는 ITEM과 KEYBOARD을 조인해서 데이터를 가져온 다음, Keyboard 객체를 생성해야 한다.
JPA의 경우 그냥 해당 객체를 저장(혹은 조회)하면 적절한 SQL을 실행해서 처리한다.
1 | // 저장 |
연관 관계 문제
Member 클래스가 Team과 연관 관계가 있다고 하자.
1 | public class Member { |
이때 Member를 조회하는 두 개의 SQL이 있다.
1 | SELECT id, name FROM USER WHERE id = ?; |
만약 굳이 Team 객체를 사용하지 않는 경우에는 첫번째 쿼리를 사용해서 Member 객체를 만드는게 낫다.
Team 객체를 사용해야 하는 경우는 두번째 쿼리로 Team 객체를 만들어서 Member 객체를 만들어야 한다.
문제는 개발자가 Member객체가 Team 객체에 값이 들어와 있는지를 확신할 수 없다는 점이다.
첫번째 쿼리로 만들어진 Member객체에게 getTeam()을 할 경우 Id만 채워진 객체가 반환되서 문제를 일으키게 된다.
그리고 만약 Team 객체에도 연관되는 객체가 있으면 쿼리는 더 복잡해질 가능성이 있다.
이 경우에도 Team 객체의 연관 객체의 데이터를 채워서 만들어 줄 것인지에 따라 SQL을 다르게 작성해야 한다.
다양한 연관관계를 상황에 따라 맞는 쿼리를 작성하는 건 상당히 힘든 작업이다.
반면 JPA에서는 연관 관계의 객체의 프로퍼티에 접근할 때 쿼리를 실행시켜서 해당 객체를 초기화한다!
1 | // 아직 Team 객체는 id값만 채워져있다. |
동일성 보장 문제
자바는 인스턴스의 주소값이 같으면 같은 객체로 분류하고, 데이터베이스는 기본키 값이 같으면 동일하다고 인식한다.
자바 객체를 저장하고 다시 조회했을 때 같은 객체를 반환하기 어렵다.
1 | public class Member { |
이런 Member 객체를 조회하려면 DB에서 조회한 데이터로 새로운 객체를 만들어서 반환하게 된다.
1 | public Member findById(String id) { |
문제는 이렇게 되면 객체를 저장하고 해당 객체를 다시 조회했을 때 같은 객체가 반환되지 않는다는 점이다.
1 | Member member = new Member(null, "name"); |
분명 논리적으로는 같은 객체인데 DB에 저장하고 찾아온 객체가 자바에서는 다른 객체로 인식하게 된다.
JPA에서는 객체를 DB에 저장하고 조회해도 같은 객체(인스턴스 주소값이 같은)를 반환해준다.
1 | Member member = new Member(null, "name"); |