a. 수송 계층 ex. TCP, UDP
일반적으로 교환 노드에는 존재하지 않음.(방화벽 같은 예외가 있다.)
엔드 시스템에만 존재
보낼 때 조각으로 나눠서 각 조각마다 헤더를 붙여서 보낸다.
받을 때는 순서대로 받지는 않는다. 받는 쪽이 수송 계층을 통해 순서를 파악한다.
b. 수송 계층 vs 네트워크 계층
네트워크 계층 : 어떤 경로로 메시지를 전달할 것인가
수송 계층 : 도착한 메시지를 어떤 프로세스로 처리할 것인가.
(프로세스들은 포트번호로 구분한다.)
c. 인터넷 수송 계층 프로토콜
순서대로 전달, 높은 신뢰성(오류 제어)(TCP)
-순서 없이 오거나, 잘못된 메시지가 오거나(비트오류),
-아예 도중에 메시지가 잃어버리거나, 같은 메시지를 여러번 받거나…
=>TCP는 이를 해결할 능력이 있음.
순서 없이 전달, 낮은 신뢰성(UDP)
두 기능 모두 속도나 딜레이를 보장하지 못한다.
d. 멀티플렉싱/디멀티플렉싱
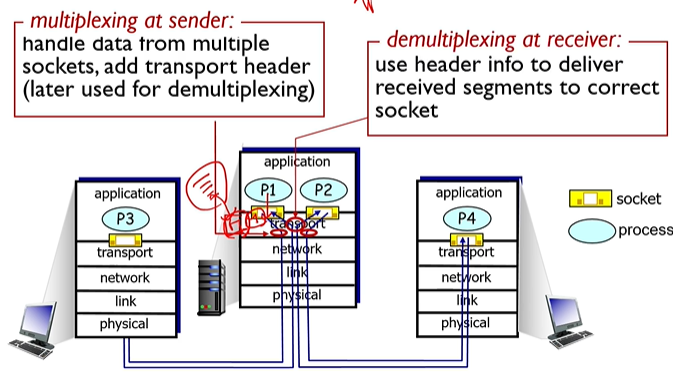
프로세스가 소켓을 통해 요청을 전달하는데,
요청들을 하나로 적절한 헤드로 담아 전달한다. 이를 멀티플렉싱이라 한다.
이렇게 전달된 헤더를 해석하여 적절한 행동을 하는 것을 디멀티플렉싱이라 한다.
디멀티플렉싱은 목적지 수송지 포트 넘버를 통해 어떤 프로세스에 전달해야할지를 파악한다.
UDP의 경우(disconnection demux) : 목적지의 포트넘버를 파악해서 포트와 연결된 소켓으로 UDP세그먼트를 전달
TCP의 경우(connection-oriented demux) : 소스 ip, 소스 포트넘버, 목적지 ip, 목적지 포트넘버가 모두 일치해야 전달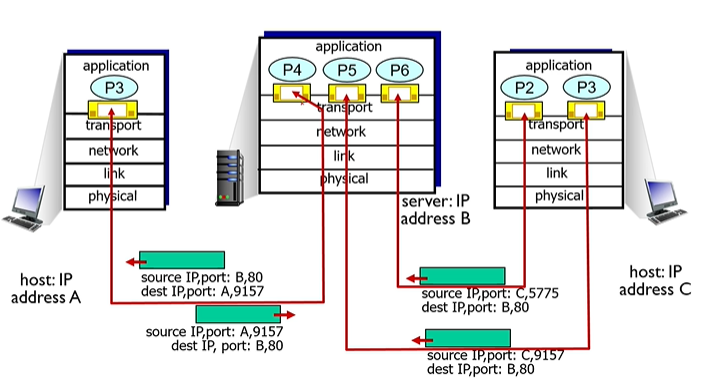
e. UDP
중간 손실이나 순서가 달라져도 특별한 액션을 취하지 않는다.
connectionless의 특징.
받는 쪽의 프로세스가 작동 중인지 확인하지 않음(no handshaking)(연결설정을 위한 초기지연이 없다)
UDP 세그먼트들은 각자 독립적으로 다뤄진다.(세그먼트들이 같이 온 세그먼트인지 관심x)
ex. DNS, SNMP
비트 손상에 민감하지 않지만 딜레이에 민감한 어플리케이션에 자주 활용(비디오, 오디오 스트림)
신뢰성 향상을 위해서는 어플리케이션 계층에서 해결해야 한다.
헤더가 단순한 구조. 사이즈가 작고 구현이 쉬움
f. UDP 헤더
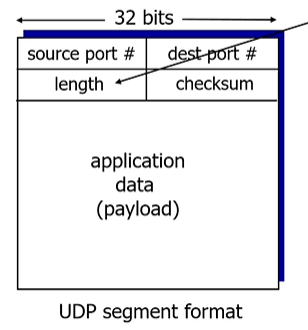
32비트 2개이므로 8바이트.
length는 헤더를 포함한 UDP 세그먼트의 바이트 길이.
checksum는 오류 발생을 확인
sender는 자기가 보낸 메시지를 특정 알고리즘의 결과값과 같이 보내고,
receiver는 자기가 받은 메시지를 특정 알고리즘에 넣은 결과값과 같이 온 결과값을 비교하여 오류를 검증
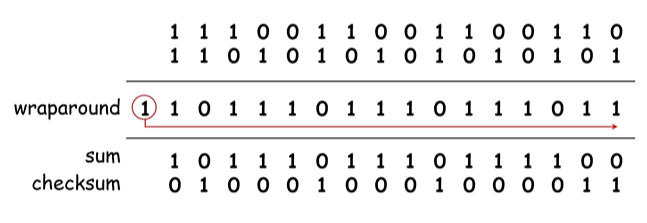
1의 보수 연산을 통해 메세지의 합과 알고리즘 결과값의 합이 0이 되는 결과값을 반환.
1,2,3,-6 => 0,3,3,-6으로 오는 경우 오류가 발생했지만 checksum으로는 못잡아낼 수 있다.
RDT
a. 신뢰성있는 데이터 전송의 원칙
패켓에 있는 헤더의 특정 정보를 해석을 통해 정보가 제대로 왔는지 확인한다.
먼저 어플리케이션 계층에서 수송계층의 RDT의 rdt_send()를 요청하면
RDT에서는 정보를 패캣으로 나눠 담고
이를 네트워크 계층의 unreliable channel에게 udt_send() 요청을 하게 된다.
네트워크를 거쳐 정보가 수송계층에 도착하게 되면 rdt_rcv()요청이 이뤄지고,
패캣의 헤더 부분을 실행하고 문제가 없으면 데이터만 꺼내서 deliver_data()요청으로 어플리케이션에게 전달한다.
b. FSM (Finite State Machines)로 rdt 프로토콜 기술
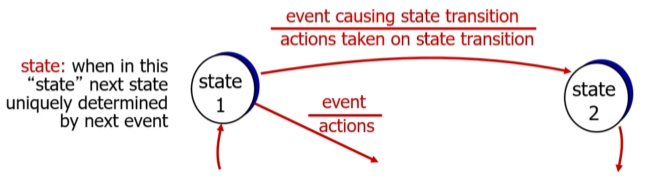
state : 프로그램이 실행되는 단계
화살표 : 프로그램의 상태 변화
event : 언제 상태변화가 이뤄지는가
action : 상태변화에 따라 프로그램이 수행할 동작
c. rdt 1.0 (오류 없는 상황 가정)
비트오류도 없고, 패캣 손실도 없고, out of order(순서오류)도 없다고 가정.
수송 계층의 부분만 표현.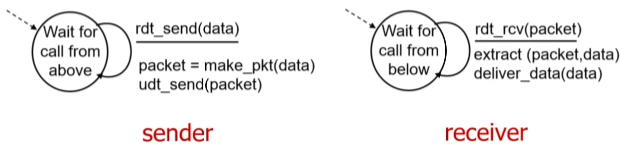
d. rdt 2.0 (비트오류가 발생할 수 있는 경우)
receiver가 재전송을 요구하거나(ARQ), 원본을 추측하여 수정해 사용한다.(FEC)
ARQ방식이 일반적.
리시버는 ACKs나 NAKs를 센더에게 반환한다.
acknowledgements(ACKs) : 문제없음.
negative acknowlegements(NAKs) : receiver가 특정 패캣에서 문제 확인=>재전송요구.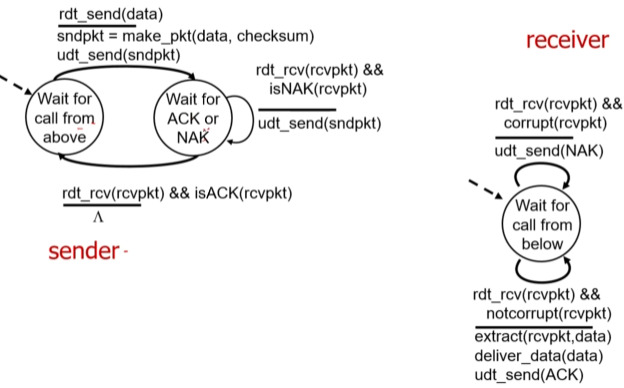
e. rdt 2.1
하지만 데이터가 아닌 컨트롤 메시지(ack, nak)에 문제가 생기면??
센더는 이런 문제를 알아차리지 못함.
이를 막기 위해 센더가 각각의 패캣에 시퀀스 번호를 붙여서 보낸다.(짝수번일땐 0, 홀수번일땐 1)
리시버는 동일한 번호로 오는 패캣을 버리는 방식으로 운용하게 된다.
이를 stop and wait(보내고 응답기다리고 응답오면 보내기이라 한다.
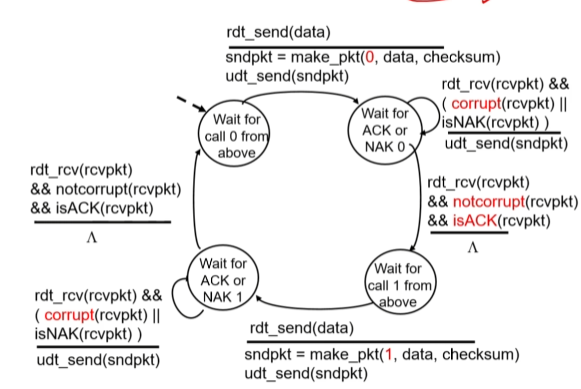
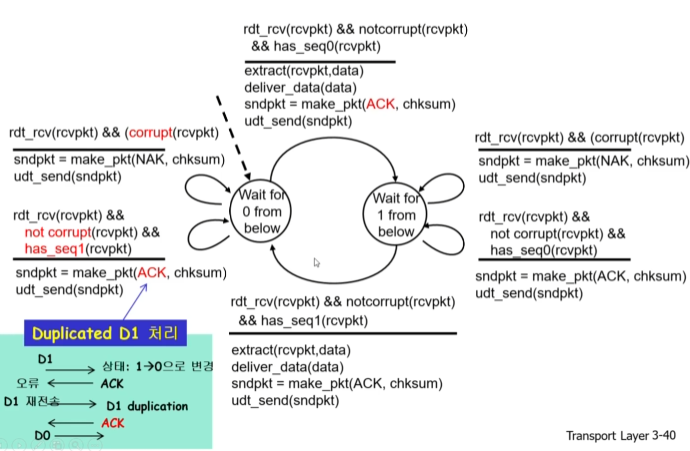
f. rdt 2.2
rdt 2.1에서 NAK를 안쓰고 ACK만 쓰는 것(기능적으로는 동일)
ACK를 보낼때 시퀀스번호를 같이 보내는 방식으로 운용
g. rdt 3.0 (패캣 손실이나 오류 발생할 경우)
센더가 패캣을 보내고 타이머를 통해 ACK가 오지 않을 경우 재전송.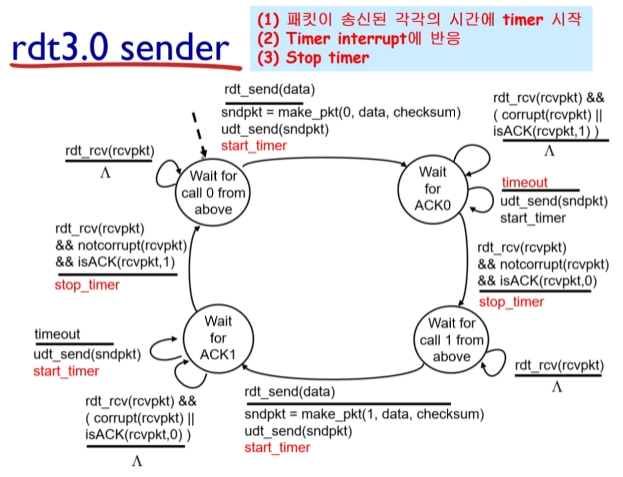
rdt 3.0은 오류 처리에는 탁월하지만, 성능이 문제다. 리시버의 신호를 기다리는 동안 회선을 낭비하는 셈.
따라서 이런 낭비를 막기위해서는 pipelined protocol. 즉 ack를 받지 않고 데이터를 여러번 보내는 프로토콜이 필요하다.
h. Pipelined protocol
ACK를 받지 않고도 다음 패캣을 보냄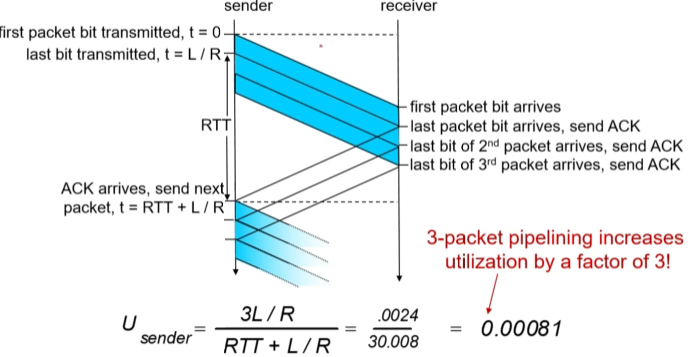
n개의 패캣을 ACK없이도 보내되, ACK가 안오면 다시 재전송해야되므로,
센더는 ACK가 모두 올 때까지 패캣을 send buffer에 저장하고 있어야한다.
h-1. Go-back-N
ACK를 반환할 때 ACK의 시퀀스 끝번호에 해당하는 ACK만 보냄
(3개의 패캣을 받으면 3번 ACK만 보냄)
(그렇다면 3번까지의 패캣은 잘 전송됐음을 의미)

센드버퍼(윈도우 사이즈)에 ack없이도 보낼 수 있는 패캣들이 존재하고,
보냈지만 ack를 아직 받지 않은 패캣 중 가장 오래된 패캣의 순서 번호를 send_base.
아직 보내지 않고 대기 중인 패캣 중 가장 빠른 패캣의 순서 번호를 nextseqnum.
센더는 ACK를 받지못한 패캣 중 가장 오래된 패캣(send_base)을 기준으로 타이머를 설정함
타이머가 만료되면(오랫동안 ACK가 안오면,) ACK를 받지못한 패캣 모두를 재전송한다.
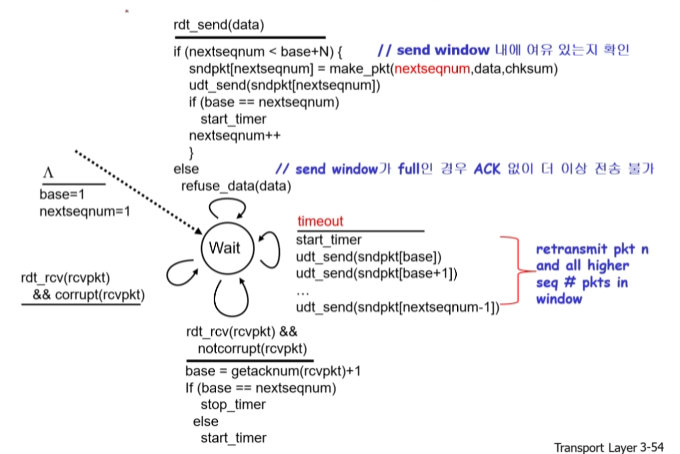
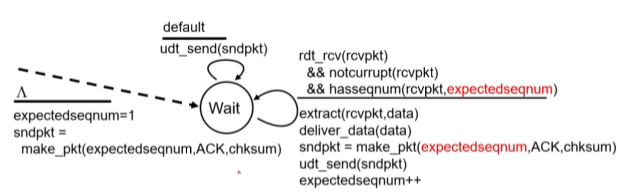
리시버는 오류 없이 순차적으로 받은 패캣 중 시퀀스 넘버가 가장 큰 값을 ACK로 보낸다.
expectedseqnum만 변수로 저장.
순서에 맞지 않은 패캣은 그냥 버려버리고 ack를 다시 보내줌(버퍼 없음)
h-2. Selective Repeat
GBN의 불필요한 패캣 버림을 줄이고, 필요한 경우만 재전송하는 방식으로 효율성을 높임
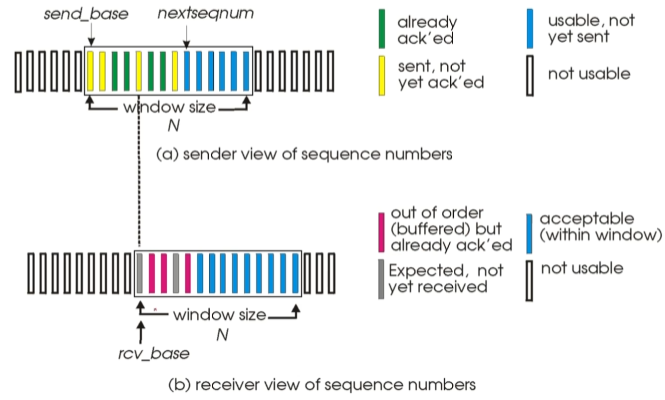
GBN과 다른점은 리시버도 윈도우사이즈(버퍼)를 갖는다는 점.
ACK를 반환할 때 개별적으로 반환.
센더는 ACK를 받지 못한 개별적인 패캣으로 타이머를 설정.
리시버는 전달받지 못한 패캣 시퀀스를 기억하고 있고 센더는 각 패캣의 타이머에 따라 패캣을 다시 보낸다.
h-2-1 Selective repeat dilemma(GBN에서도 발생)
만약 시퀀스 넘버를 0,1,2,3으로 채택해 사용한다고 가정.(2비트일때 표현 가능한 수가 0123)
윈도우 사이즈는 자연스럽게 3
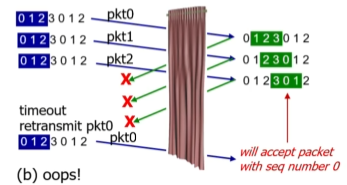
마지막에 센더가 재전송한 pkt0을 리시버가 4번째 패캣으로 받아들일 문제가 생긴다!!!
이것을 해결하려면 윈도우 사이즈를 줄여야한다.
=>시퀀스 넘버에 쓰이는 비트 수 = n일때, 윈도우 사이즈는 2^(n-1)
=>2비트인 경우, 윈도우 사이즈는 2로 해야함
=>GBN의 경우 2^n-1
TCP
a. TCP의 특징 간단요약
point to point : 한 리시버와 한 센더가 참여.
신뢰성(rdt지원), in order 지원
pipelined 형식(버전에 따라 gbn, selective 형식 지원)
센드 버퍼와 리시브 버퍼 존재
한 연결에서 양방향 데이터 흐름
connection oriented(handshaking) 센더와 리시버의 상태정보를 기억.
flow controlled 처리 속도보다 전송 속도가 빠를 경우 속도를 조절.
b. TCH 헤더
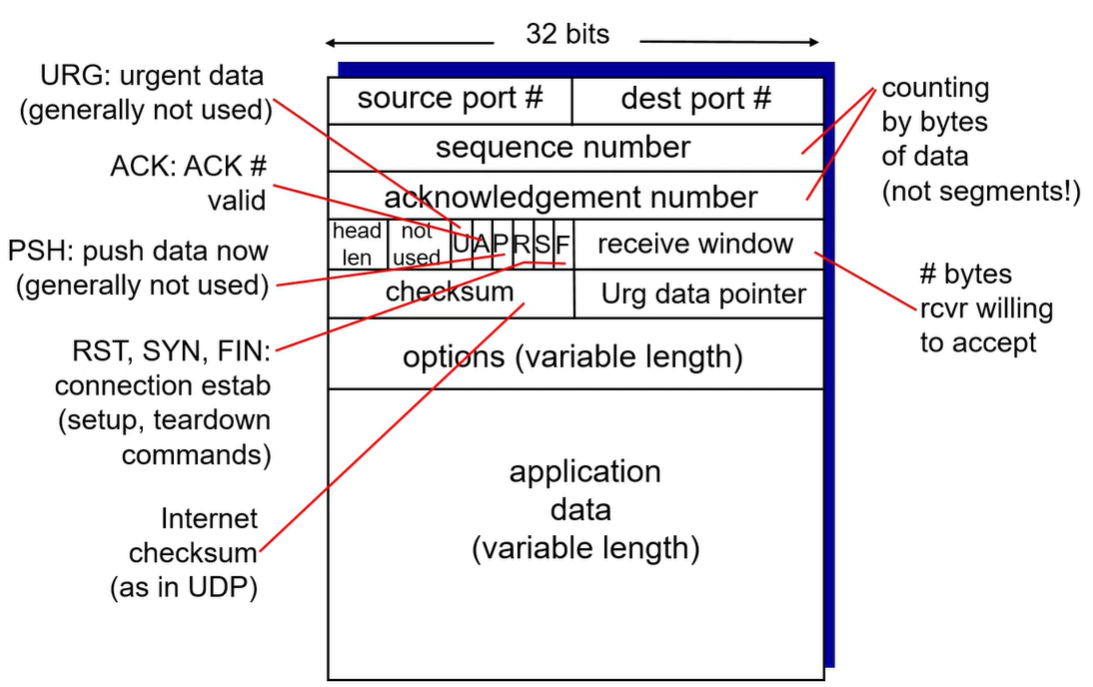
sequence number, ack => rdt에 사용되는 기능
시퀀스 번호와 ack는 바이트 단위당 1씩 늘어간다.
head len(head length) : 디폴트 헤드 20바이트 + option의 길이를 확인. option의 존재 유무 파악
UAPRSF =>모두 1비트(0과 1 값만 가질 수 있음)
U 잘 안쓰임.
A ack가 유효한가?
P 잘 안쓰임.
R reset. 연결리셋 연결강제종료
S sync. 연결
F final. 연결종료
recieve window : 리시버가 현재 받을 수 있는 데이터 량. 플로우컨트롤에 활용
check sum : udt에서 check sum과 동일한 기능
urg data pointer : 잘 안쓰임
option : 있을 수 있고 없을 수도 있는 가변기능(특별한 경우 아니면 잘 안쓰임)
c. TCP timer
TCP는 데이터에 대한 ack가 정해진 시간내에 오지 않으면 보낸 패캣을 재전송한다.
이때 정해진 시간을 재는 타이머를 너무 길게, 너무 짧게 설정하면 피해를 본다
길게 하면, rtt(데이터가 전송되고, ack가 오는 데 걸리는 시간)이 끝나도 다른 패캣을 보내지 않기 때문에 시간적인 손해를 본다.
짧게 하면, 정상적으로 ack가 오고 있는데 패캣을 재전송하는 불필요한 작업을 하게 될 수 있다.
TCP는 timer를 여유있게 하는편.
SampleRTT(측정값)를 다 모아 정규분포 95%의 신뢰도로 타이머를 설정.
하지만 매번 SampleRTT는 매번 달라져 정규 분포 모양이 달라짐.=>SampleRTT 수집방식은 사용할 수 없음.
대신 exponential weighted moving average를 사용
EstimatedRTT (특정 시점에서의 RTT의 가중평균)를 통해 대략적인 평균 RTT를 예상.
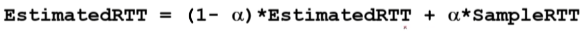
이를 활용해서 타이머는 EstimatedRTT에 약간의 여유를 줘서 준다.
여기서 약간의 여유는 DevRTT(분산값)을 이용한다.
즉 TimeoutInterval = EstimatedRTT + 4*DevRTT로 한다.
a. TCP의 rdt(신뢰성 있는 데이터 전송)
TCP는 ip의 위에서 rdt 서비스를 제공한다.(ip는 신뢰성 없음)
-pipelined 방식 사용(gbn selective 선택 사용)
-cumulative ack(누적 ack 방식 사용)
-보냈는데 ack를 받지 못한 패캣에 해당하는 타이머 하나를 운용
b. TCP sender
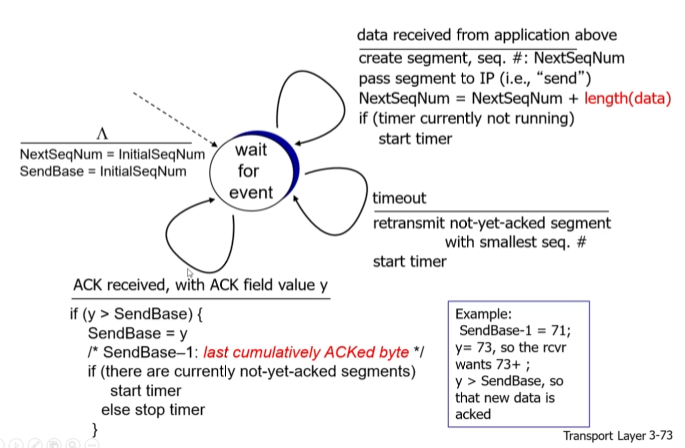
초기에 NextSeqNum과 SendBase를 초기화.
상위 계층이 데이터 전송을 요구할 때, nextseqnum에 해당 되는 데이터를 세그먼트 생성하고,
nextseqnum을 생성된 데이터 만큼 뒤로 보내고 타이머 실행.
타이머가 다 되면,보냈는데 ack를 못받은 데이터 중 시퀀스 넘버가 가장 작은 놈을 다시 보내고 타이머 재시작.
ack를 받으면 sendbase를 ack까지 옮김
만약 아직 받지 못한 ack가 있다면 타이머를 시작하고 그렇지 않으면 타이머 종료
c. TCP ack generation
| event at receiver | TCP receiver action |
|---|---|
| 예상한 패캣이 오고 해당 패캣 이전까지는 ack 보냈음 | 혹시 다른 패캣이 올지 모르니 500ms 기다린 후 안오면 해당 ack를 보냄. |
| 예상한 패캣이 왔는데 해당 패캣 이전에 ack를 안보낸 패캣이 있음 | 즉시 cumulative ack(누적ack)를 보냄 |
| 예상한 패캣보다 시퀀스 번호가 큰 패캣이 온 경우(gap detected) | 바로 중복된 ack를 보냄.(지금까지 잘 받은 ack, 리시버가 기다리는 시퀀스 넘버이기도.) |
| 갭을 채우는 패캣이 왔을때 | 바로 해당 ack를 보냄 |
| |
d. TCP fast retransmit
타이머가 커질 수록 재전송할 때까지 기다리는 시간이 길어지게 된다.
=>이런 시간을 줄이려는게 fast retransmit
센더가 여러 세그먼트를 계속해서 보낼 때,
만약 어떤 세그먼트가 없을 경우 리시버는 동일한 ack를 중복해서 계속 보내게 된다.
이럴 경우 센더가 세번의 중복 ack를 받을 경우
타이머를 기다리지 않고 ack를 받지 못한 시퀀스번호가 가장 작은 세그먼트를 바로 재전송한다.
e. TCP flow control
센더가 보내는 양이 리시버가 처리하는 양보다 너무 많으면 이를 조절하는 기능
리시버는 헤더의 receiver window라는 곳에 현재 TCP 리시버 버퍼(RcvBuffer)에
남은 공간(rwnd)이 얼마나 있는지를 작성해서 ack에 담아 전송함.

e. TCP connection management
리시버와 센더가 서로간의 상태정보(초기 시퀀스넘버, 센더버퍼 사이즈, 리시버버퍼 사이즈)를 연결을 시작할 때 서로 교환
하지만 TCP는 2way handshaking을 사용하지 않음
=> 응답을 보내고 대답을 듣는 시간이 가변적임.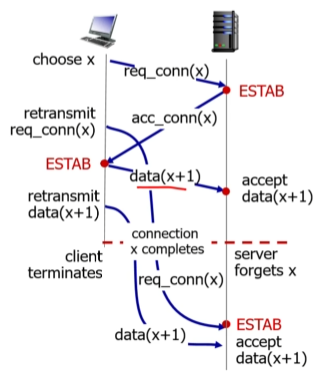
리시버의 재전송시간이 센더의 타이머보다 늦다보니, 센더가 연결 요청을 다시보내게 되고,
다시 보내게 된 연결에 따라 data를 전송하게 된다.(x를 보내야 되는데 x+1을 보내게 됨)
이렇게 데이터를 전송한 이후 연결을 닫으면 재전송한 연결요청의 답을 들을 수 없게 된다.
그래서 TCP는 3way handshaking을 함
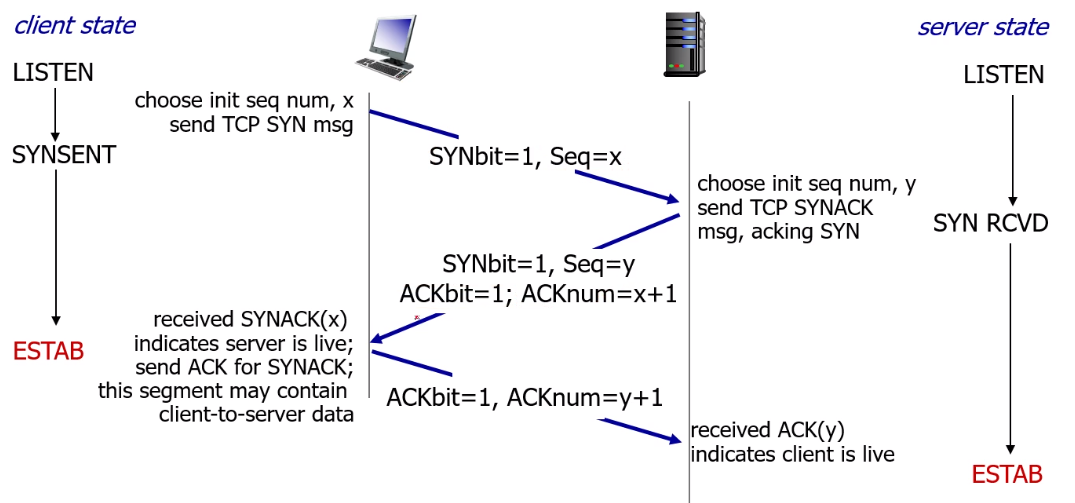
헤더에 있는 syn을 통해 연결 유무를 판단하고, 양방향 연결을 함.(x,y는 임의의 값)
이때 acknum=x+1은 비록 연결요청에는 데이터 값이 없지만, 요청 자체가 1비트라고 여겨서 acknum에 +1된것.
3 way handshaking은 연결을 닫을 때도 특이하다.
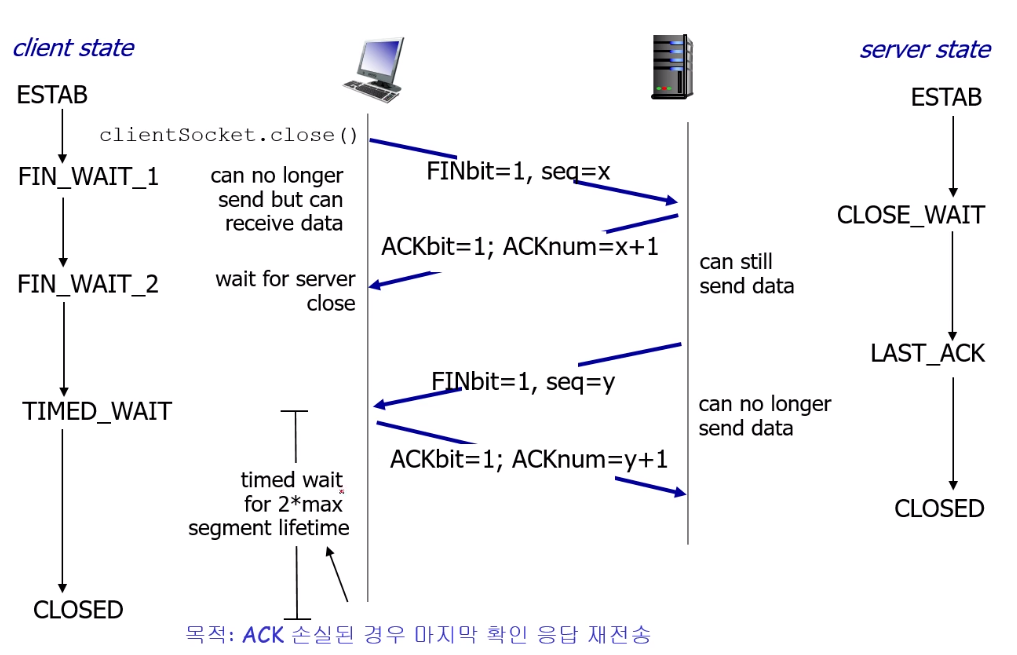
클라이언트가 먼저 연결을 종료한다고 가정한 상황이다.
헤더에 있는 fin을 활용해 연결 종료 의사를 밝힌다.
이것이 전달되면 서버도 ack를 통해 클라이언트의 연결 종료 의사를 확인한다.
(이때 중요한 건 서버 쪽은 연결을 종료하지 않았다는 것이다. 단지 클라이언트가 연결, 즉 전송을 종료했을 뿐이다.)
그리고 마지막으로 서버도 종료 의사를 전달하여 클라이언트가 받았을 때 클라이언트는 잠시동안 대기한다.
왜냐면 클라이언트가 보낸 종료ack가 서버에 잘 전달 안됐을 수 있기 때문이다.
(잘 전달되지 않으면 서버는 종료의사를 다시 재전송하게 된다.)
TCP 혼잡제어
a. 혼잡
혼잡의 원인 : 라우터에 들어오는 양이 처리량보다 더 커서. 딜레이가 길어지고, 패켓을 잃을 수 있음.
라우터의 버퍼가 무제한이라고 가정하면. 데이터 전송이 계속 커질 수록, 데이터 전송 능력(throughput)능력은 같이 오르다가 한계 이후는 정체된다.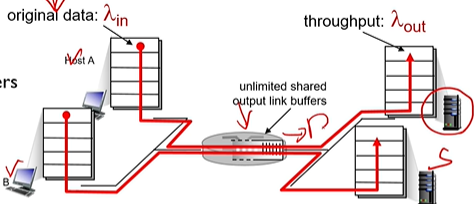
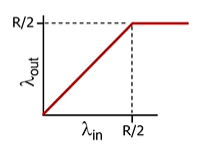
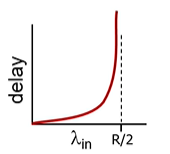
하지만 현실엔 다름(라우터 버퍼가 유한함)
실제로 유효하게 받은 데이터 처리량을 goodput이라고 한다.
혼잡이 발생하면 라우터에서 로스가 발생-수신자가 재전송-이럴 경우 재전송 데이터는 goodput에는 포함되지 않음.
즉 혼잡이 발생하면 goodput과 throughput이 차이가 나게 된다!
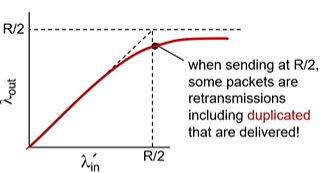
여러 센더가 라우터들을 공유하면서 정보를 전송할 때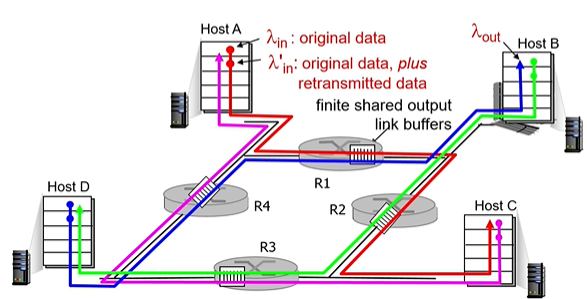
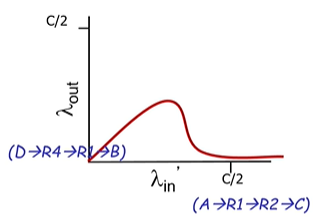
g호스트 D가 B를 향해 데이터를 주고, A가 C를 향해 데이터를 전송한다고 가정.
이때 R1라우터를 같이 사용하게 된다.
이때 A가 데이터 전송량을 늘리게 되면? B가 받는 정보량이 줄어들게 된다.
그리고 R1에서 생긴 패캣로스를 다시 재전송하게 되면 R4는 억울하게 정상적으로 했던 일을 다시 또 하게된다.
이를 upstream trasmission cpacity의 낭비라고 한다.
b. 혼잡 제어
TCP의 혼잡제어는 해당 라우터를 사용하는 모든 참가자가 다같이 속도를 내리는 방식.
b-1. additive increase multiplicative decrease AIMD방식
congestion avoidance 상태에서 적용(전송이 어느정도 진행되고 있을 때 너무 많은 데이터전송을 막음)
센더는 네트워크의 혼잡도를 잘 모르니 작은 데이터 먼저 한번 보내보고,
잘 보내졌음을 알게되면, 더 많은 데이터를 보내보고,
이 또한 잘 보내졌으면, 더욱 많은 데이터를 보내고…
(딜레이나 로스가 발생하게 되면 전송률을 낮춰서 다시 반복)
센더는 cwnd(혼잡제어 방식에 있어서 보낼 수 있는 데이터량), rwnd(플로우컨트롤에 의해 보낼 수 있는 양)), sender widow(rdt에서 보낼수 있는 데이터량) 중 가장 작은 값만큼 데이터를 보내기로 정한다.
TCP sending rate = cwnd/RTT(대략적으로)
b-2. TCP slow start
slow start는 센더가 맨 처음 데이터를 한 세그먼트만 보내보는 것을 의미.
잘 보내졌으면 두 세그먼 트를, 그 다음엔 네 세그먼트를… 이런식으로 2^n를 하며 전송 데이터를 늘려감.
이렇게 데이터를 늘려가다가 혼잡하게 되면, AIMD로 제어.
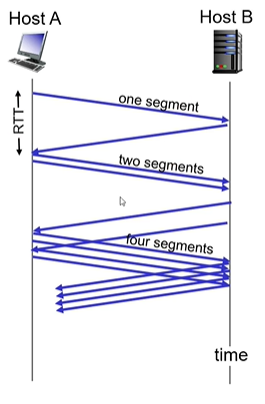
초기엔 cwnd= 1 mss(최대로 보낼 수 있는 세그먼트량)
매 RTT마다 두배로 늘림.
c. 데이터 전송 줄이기
timeout이 발생하거나, 중복된 ack가 세번오면 로스로 간주한다.
timeout이 발생 시(TCP Tahoe, 구버전), 전송량(cwnd)를 1mss로 재설정함. 다시 slow start 과정을 진행시킴.
slow start 이후로 어떠한 임계값(threshold, 정해진 변수)보다 전송량이 커지게 되면, 선형적으로 증가함.
TCP Tahoe는 항상 cwnd를 1mss로 만듬(다른 방식을 지원 안하니..)
중복 ack가 세번 온 경우(TCP RENO , 신버전), 전송량(cwnd)를 절반으로 낮춤. 그리고 나서 선형적으로 증가(slow start)아님.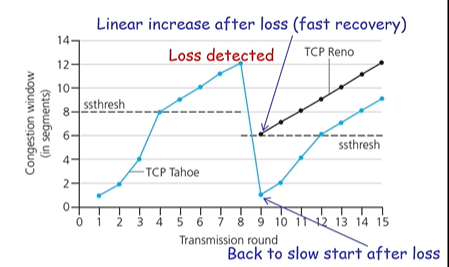
| 상태 | 이벤트 | TCP 센더 대응 | 비고 |
|---|---|---|---|
| Slow Start(SS) | 전에 보낸 데이터의 ack를 정상적으로 받음 | cwrd가 threshold보다 큰 경우 CA로 변환 | 매 RTT마다 cwrd를 두배로 |
| Congestion Avoidacne(CA) | 전에 보낸 데이터의 ack를 정상적으로 받음 | 매 RTT마다 cwrd를 1 mss씩 증가(additive increase) | |
| SS or CA | 중복된 ack를 세번 받음 (로스 감지) | threshold를 cwrd의 절반으로 cwrd를 threshold로 하고 CA로 변환 | Fast Recovery(threshold부터 증가) |
| SS or CA | timeout(로스 감지) | threshold를 cwrd의 절반으로 cwrd를 1mss로 하고 slow start 상태로 전환 | slow start 진행 |
| SS or CA | 중복된 ack | duplicate ack 카운트만 증가 | cwrd나 threshold는 변경 안함 |
d. TCP throughput
throughput = 시간당 전송률
TCP의 throughput은 복잡하므로 간단한 가정이 필요.
slow start 상태는 제외, 항상 보낼 데이터가 존재함을 가정.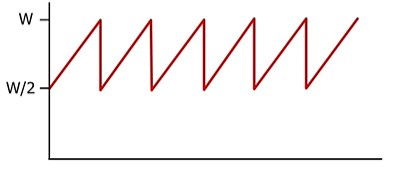
w=로스가 발생할때 cwrd
평균 cwrd는 3/4w
평균 throughput은 3w/4rtt
이때 가정을 제외하고 현실적인 Throughput은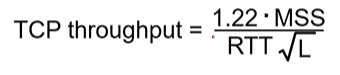
이때 L은 로스 발생 확률이다.
e. TCP Fairness
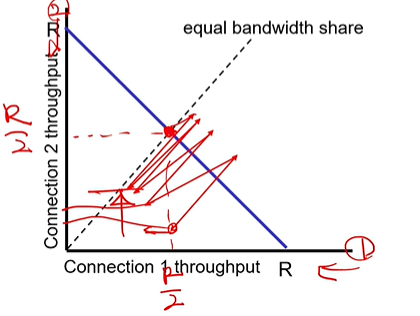
TCP는 여러 사용자가 라우터를 이용하면 결과적으로는 동일한 양의 리소스를 사용하게 된다.
두 TCP사용자가 한 라우터를 이용하고, 라우터의 처리양이 100이라고 할 때,
(60,20)-전송량 증가-(80,30)-로스발생(값 절반으로 나눔)-(40,15)….이런식으로 가면 결국 (50,50)이됨.
e-1 TCP Fairness의 한계
UDP와 라우터를 공유하는 경우
-UDP가 자원을 더 가져갈 수 있음!
TCP를 여러개 사용할 때(여러 프로세스 사용)
-여러 TCP를 운용하는 호스트가 자원을 더 가져갈 수 있음!
e-2 Explicit Congestion Notification
혼잡이 아닌 다른 경우에 ack를 받지 못하는 경우도 존재한다.
근데 이런 경우에도 속도를 줄이는 것은 비효율적!
이를 해결하기 위해 네트워크에서 혼잡을 일으킨 호스트에게 혼잡임을 알리게 하자.
IP헤더의 Tos필드에 혼잡여부를 기록해서 센더에게 전달!
하지만 많이 사용되지 않음(모든 라우터가 이 기능을 갖춰야하기때문에..)