a. 쿠키 User-server state : cookies
서버가 유저의 상태를 기억하기 위한 쿠키(주문내역 등)
맨 처음 유저가 브라우저로 사이트를 방문할 경우 생성
이후 해당 브라우저로 사이트 방문시 쿠키를 통해 특정 액션을 취함.
b. 쿠키의 네가지 구성요소
1. HTTP 응답메시지에 있는 쿠키 헤더라인
2. 다음 HTTP 요청 메시지에 있는 쿠키 헤더라인
3. 사용자의 브라우저가 관리하는 쿠키파일
4. 웹사이트의 백엔드 데이터베이스
하지만 보안 상의 위험이 존재.
c. 웹 캐쉬(프록시 서버)
목적 : 클라이언트의 요구가 근본 서버에 관여하지 않고 안정화하자.
(origin server가 클라이언트와 거리가 멀 경우..)
프록시 서버(캐쉬)에 주변 클라이언트가 자주 사용하는 데이터를 저장해놓음
만약 프록시 서버에 없는 내용을 클라이언트가 요구할 경우,
프록시 서버는 origin서버에 해당 데이터를 요구
캐쉬는 클라이언트와 서버의 역할을 모두 수행
캐쉬 사용 시 응답 시간을 줄이고, 액세스 링크의 트래픽을 줄임
d. Conditional GET
캐쉬나 클라이언트에 컨텐츠가 있는 상황에서
오리진 서버의 컨텐츠가 변경되었을 경우 동기화를 하기 위한 기능
if-modified-since
변경된 값이 존재할 경우 200(OK), 그렇지 않을 경우 304 Not Modified
e. E-mail
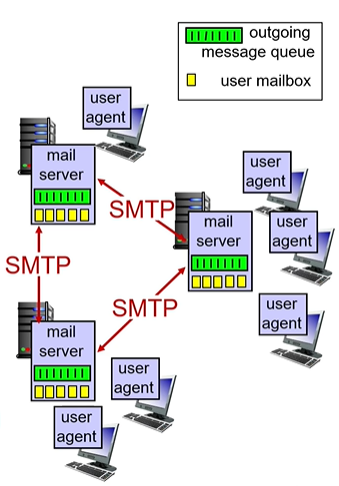
세가지 큰 요소
유저 에이전트-메일서버-SMTP(simple mail transfer protocol)
유저 에이전트: 메일을 읽고 , 수정 수행. 서버에 저장된 메시지를 가져오거나 보냄.
메일 서버 : 유저로부터 메일을 받음. 보낼 메일들을 메세지 큐에 담음.
SMTP : 메일 서버 간 연결해주는 역할
f. SMTP
reliably transfer를 위해서 TCP를 이용. 포트 번호 25번
direct transfer : 서버끼리 통신은 직접한다.
transfer는 세가지 단계를 거친다 (handshaking-transfer-closure)
메세지는 반드시 7비트 ASCII코드로 이뤄져야한다.
SMTP는 persistent연결을 사용
메세지 종료는 마침표(.)로 결정.
g. HTTP와 SMTP의 비교
HTTP는 클라이언트의 요구를 서버가 응답하는 것(pull)
SMTP는 클라이언트의 데이터를 서버가 받아 저장하는 것(push)
둘 다 ASCII 커맨드/응답 상호작용과 status code를 사용.
HTTP는 매 오브젝트를 캡슐화해서 하나의 응답 메시지로 보냄
SMTP는 여러 오브젝트를 한번에 싹 가져온다.
h. 메일 메세지 포맷
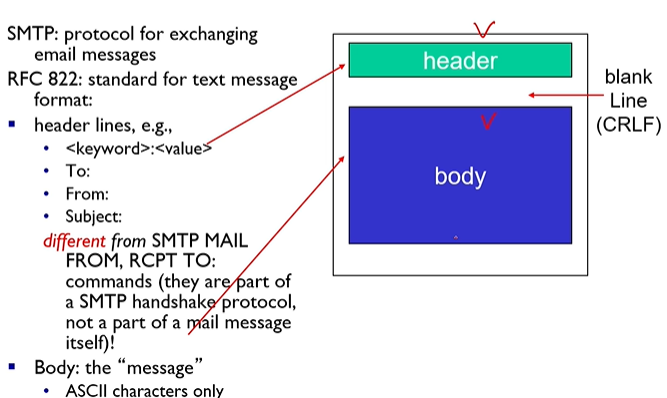
i. 메일 액세스 프로토콜
-메일 서버에 직접 접근하지 않고 내 pc에서 처리하는 프로토콜
-pop3 : 권환확인, 메시지 불러오기, 메시지 삭제 등 지원
download and delete (서버에서 불러오면 서버는 비움)
download and keep (삭제해도 복사본을 서버가 갖고 있기)
-imap : 서버에서 모든 메시지를 보관, 클라이언트가 접속해서 사용
동기화에 유리, 메시지 중 일부만 보기 가능.
DNS
j. DNS : domain name system
각각의 노드들을 식별하기 위한 id가 필요하다.
대표적인 예시로 ip 주소(32비트)를 활용한다.
www.something...com이라는 는 주소로 들어갈 경우
DNS가 이 도메인주소를 ip주소로 변환하여 컴퓨터들이 인식할 수 있게한다.
분산데이터 : 계층적인 구조를 갖는 네임서버들
어플리케이션 계층 프로토콜 : UDP를 사용
k. DNS : services
host aliasing : 실제 이름을 줄여서 사용할 수 있게 해준다.
예를 들어 www.abcd.ef...com을 www.abcd.com 으로도 접속 가능하게 지원한다.
mail server aliasing : 메일서버도 별명을 활용할 수 있다.
load distribution : 하나의 웹서버가 모든 요청을 다루기 보다 여러 웹서버가 나눠서 다루는 게 효과적.
하나의 도매인에서 여러 ip로 나타내게 하여 요청을 나눠서 다룰 수 있음.
왜 DNS는 분산 형식을 가질까?
하나로 모았을 경우 DNS 하나가 망가지면 모두 접속하기 어려워짐
한 DNS에 너무 많은 트래픽이 몰림
유지보수에도 불리
l. DNS : 계층구조
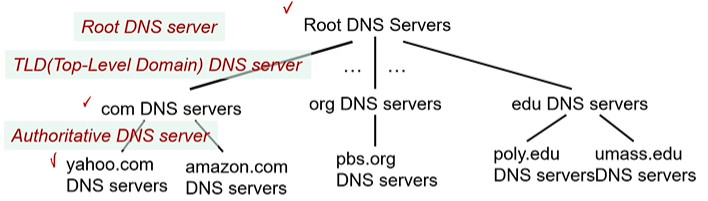
예시. amazon.com을 입력했을 경우
1. Root DNS 서버가 TLD DNS 서버 중 com DNS 서버를 찾아 전달
2. com DNS 서버는 amazon.com의 DNS 서버를 찾아줌
3. amazon.com DNS 서버는 해당 ip를 찾아줌
그 외로 local DNS name 서버가 있음.
-사용자와 근접하게 작동. 계층 구조에는 포함 안됨.
-사용자가 어떤 도매인을 입력하면 해당 도매인에 캐쉬가 있는지 확인하고
-있으면 해당 ip를 반환하고, 없을 경우 프록시로 동작하여 쿼리를 계층구조로 요청을 보냄
n. DNS 작동 방식
iterated query : local DNS 프록시 역할로 여러 서버와 연결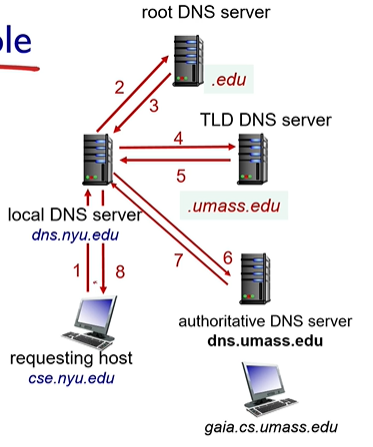
recursive query : local DNS가 계층 구조에 일을 넘김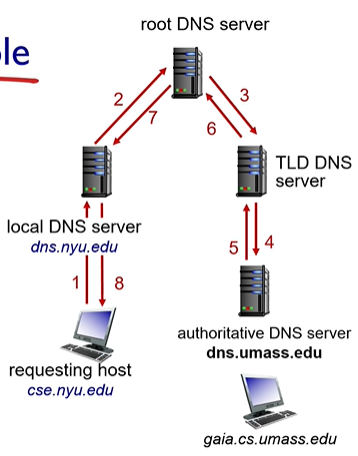
m. DNS 캐싱
이전에 접속했던 쿼리에 대한 ip를 일정기간동안 기억하고 있다.
일정 기간(TTL) 이후 해당 매핑을 지운다.
자주 방문하는 쿼리의 TLD서버를 local name 서버가 캐시해놓는다.
o. DNS 레코드
RR : DNS에 저장되는 데이터의 형식
RR format: (name, value, type, ttl)
type에 따른 형식 변화
-type=A : name은 호스트이름, value는 ip주소
-type=NS : name은 도매인주소, value는 authoritative name server의 호스트이름
-type=CNAME : name은 alias name(별명), value는 canonical name(원래 이름)
-type=MX : name은 메일서버의 alias name, value는 canonical name
p. DNS 프로토콜
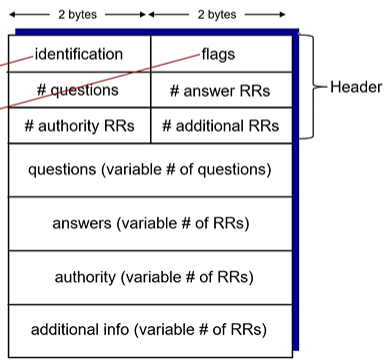
identification : 어떤 query에 대한 응답인지를 구분해주는 역할
flag :
QR(1비트) : 쿼리인지 응답인지
Op code(4비트) : 0(일반적인 쿼리 혹은 응답), 1(inverse query), 2(서버 상태 요청), 4(주의), 5(업데이트)
q. DNS에 새로운 레코드 삽입
-DNS reigistar 사업자에게 도매인과 해당 ip를 매핑
P2P
r. pure P2P 구조
-항상 켜져있는 서버가 존재하지 않음
-end system 끼리 직접 통신하게 된다.
-이 end system을 peer라고 부른다.
-한 서버가 여러 end system에게 전송하는 거 보다 end system끼리 자료를 주고 받게 하는 P2P가 더 확장성이 있음.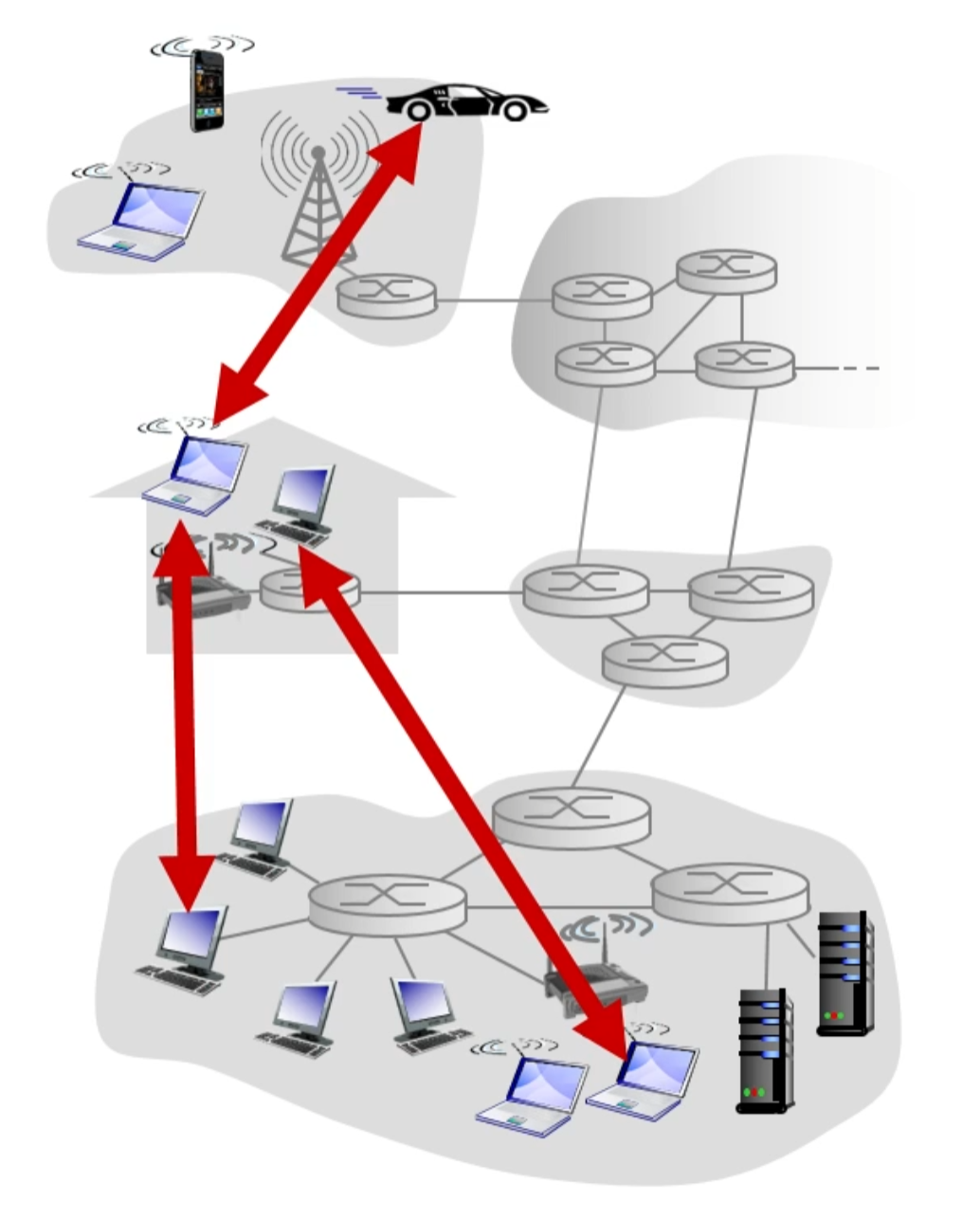
s. Bit-torrent
파일을 256kb의 청크로 나눠 peer들 끼리 청크를 주고 받는 형식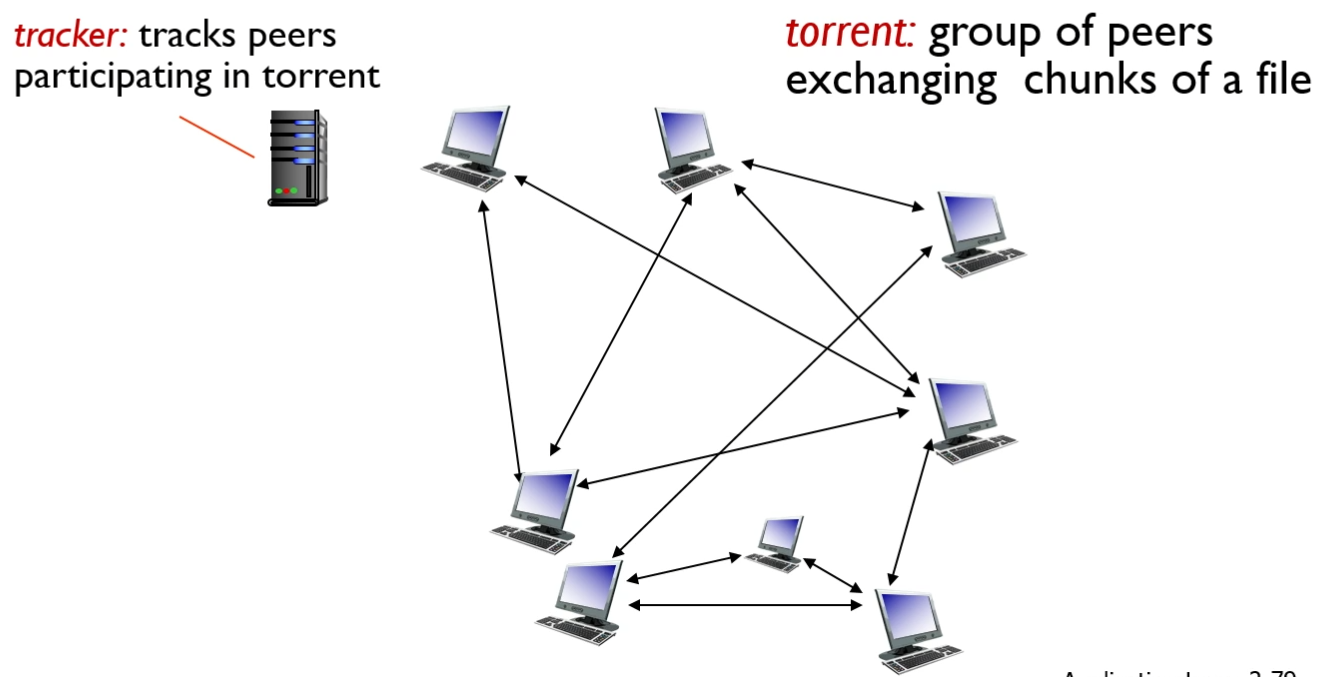
traker는 피어들이 누구인지, 누가 참여하고 있는지를 추적하는 장치.
만약 새로운 피어가 들어왔을 때 이 피어는 트래커를 통해 어떤 피어와 연결해야하는지를 알 수 있다.
청크는 내 이웃 피어들에게서 가져오는데, 이때 청크는 가능한 희귀한(피어들이 덜 가지고 있는) 청크를 가져온다.
청크를 보내는 기준은 나에게 많은 청크를 보내준 피어에게 청크를 보내주는 식이다.
10초마다 청크 수송신 상황을 점검하고, 30초마다 랜덤한 피어에게 무조건으로 청크를 보내준다.
CDN
t. DASH (Dynamic, Adaptive, Streaming over HTTP)
서버에서는 비디오 파일을 여러개의 청크로 나누고
청크들을 여러 방법으로 인코딩하고 저장
manifest file : 다양하게 저장된 청크들이 어디에 저장됐는지(URL) 알려주는 파일
클라이언트에서는 서버-클라이언트 대역폭(다운로드 속도)을 측정해서
속도에 따라 manifest가 적당하게 인코딩된 청크 위치를 찾아 보내준다.
u. CDN
지역적으로 여러개의 서버를 두고 중앙서버로 연결.
enter deep : 네트워크 엣지에 CDN을 설치하는 방법. 유저와 가깝고 성능도 좋지만..
CDN의 수가 많아지고 관리하기도 힘들다
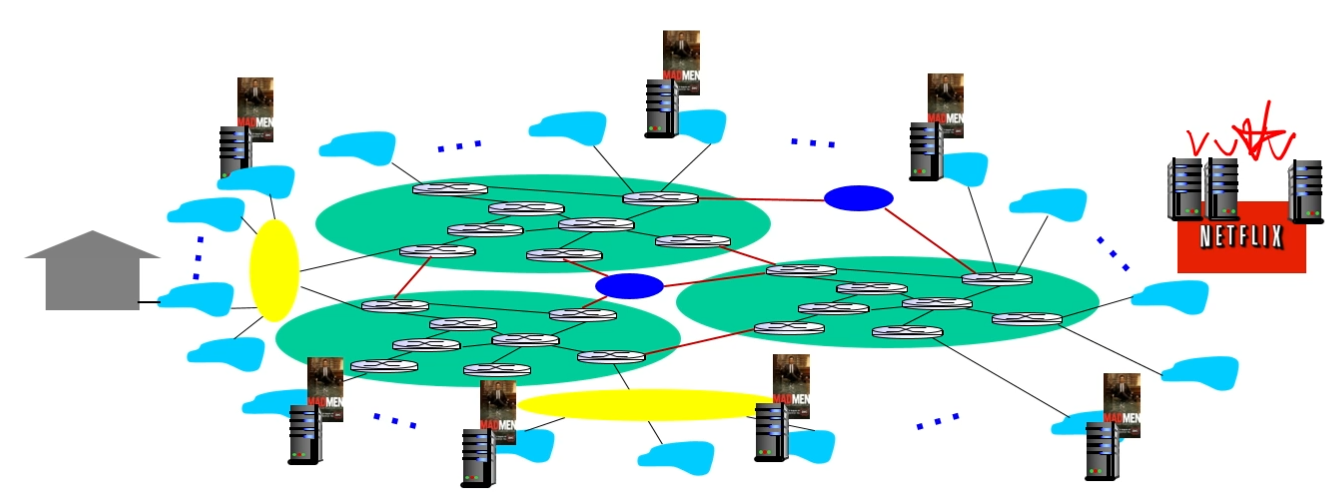
bring home : 네트워크 엣지가 아닌 ISP코어에 저장하는 방법