스프링 부트 동작원리
- 톰캣
- 필터
- 권한, 인증, 인코딩…
- 디스패처
- 요청된 주소에 맞는 컨트롤러를 호출
<얘네는 요청때마다 메모리에 로딩>
<요청이 올 때까지 대기>
재사용하는 게 아니라 새 쓰레드를 사용함
4. 컨트롤러
- 요청에 포함된 데이터 받음, 다른 서비스 호출..
5. 서비스
6. JPA 레포지토리
7. 영속성 컨텍스트
- 데이터소스
- DB와 연결
- view Resolver
- 페이지를 만들어서 응답. 일반적인 컨트롤러일 때 작동
- RestController일 땐 작동 x
- 세션
- 인터셉터
- 보안에 민감한 함수가 실행 직전에 요청자가 권한을 가졌는지 확인
소켓 통신과 http 통신
Socket : 운영체제가 가지고 있는 소통 창구 같은 것!
한 포트에서 소캣을 열어서 다른 컴퓨터와 연결을 확인하고,
다른 포트에서 소캣을 열고 스레드를 할당해 해당 연결을 진행하게 한다.
그와 동시에 연결을 확인하는 소캣은 계속 열어두어서, 다른 컴퓨터가 연결 요청을 할 수 있다.
이런 소켓통신은 여러 컴퓨터가 계속 연결되어 있기 때문에 부하가 크다!
이런 단점을 해결하는게 stateless 방식의 http 통신!!
http는 문서를 전달하는 방식이다.
http는 한 소켓에서 요청을 받아서 응답을 해주고 해당 컴퓨터와 연결을 끊는다.
부하가 적지만, 다시 연결하려면 매번 새로운 연결을 만들어야 한다.
그리고 서버가 클라이언트를 기억하지 않는다.(웹서버는 이를 해결한다.)
1. 내장 톰캣을 가진다.
웹서버(스프링에선 아파치)란?
클라이언트가 원하는 자료들을 가지고 있고, 클라의 request를 받고, url,uri (자원을 요청하는 주소, 식별자에 접근하는 주소)에 따라
적절한 자원(정적인 자원 static)을 응답해서 보낸다!
하지만, 이 중에 만약 자바 코드(.jsp)로 이뤄진 자원을 요청받으면, 아파치는 이를 다루지 못한다.
(웹 브라우저도 html, css, js 파일정도만 이해할 수 있으니까… 자바파일은 이해못한다.)
그래서 이럴 경우 톰캣에게 이를 처리하도록 한다.
톰캣이란? 자바 파일(.jsp)를 컴파일하고, html로 만들어 아파치에게 돌려주는 역할을 한다.
톰캣은 요청객체와 응답객체를 알아서 메모리에 생성한다.
2. 서블릿 컨테이너
스프링은 url으로는 접근이 불가능하다. uri로 접근만 가능하게 했다.
그래서 특정한 파일을 요청을 할 수 없다는 의미다!!
결국 요청할 때는 무조건 자바를 거쳐야 된다.(즉 톰캣을 거쳐야!)
서블릿? 자바로 웹할 수 있게 한 것.
서블릿 컨테이너? 서블릿의 집합(여기서는 톰캣을 의미.)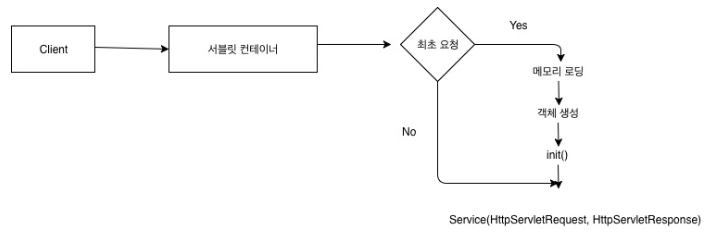
서블릿 컨테이너에서는 최초 요청이 오면, 스레드를 생성해서 서블릿 객체를 만든다!
(왜 스레드를 만드냐? 여러 요청이 동시에 올 수 있으니까!, 동시접근 허용.)
우리가 최대 스레드를 20개라고 설정했으면 스레드가 20개가 될 때까지 새 스레드를 만들어서 서블릿 객체를 만든다.
이때 20개의 요청을 처리하여 20개의 서블릿 객체를 서블릿 컨테이너에 만들었다고 가정하면
다음 요청때는 만들어진 서블릿 객체를 다시 재사용한다!
3. web.xml
서버를 하나의 성으로 비유하면,
web.xml은 서버의 문지기와도 비슷하다.
-ServletContext의 초기 파라미터 : 일종의 암구호
-Session의 유효시간 설정 : 들어온 사람이 누구인지, 얼마나 있을지
-Servlet/JSP에 대한 정의 : 들어온 사람의 성 속 목적지를 인식(식별자 인식)
-Servlet/JSP 매핑 : 들어온 사람의 성 속 목적지로 가는 길을 안내(식별자에 따른 자원 매핑)
-Mime Type 매핑 : 들고오는 데이터 타입(mime type)을 성에 맞게 매핑
-Welcome File list : 아무 이유 없이 온 사람들을 보내는 곳
-Error Pages 처리 : 잘못된 목적을 가지고 온 사람들을 보내는 곳
-리스너/필터 설정 : 잘못된 성을 온 사람이나, 맞지 않는 사람을 못들어오게 함
(리스너는 문지기를 도와 같이 들어오는 사람을 특정한 조건을 확인하는 역할)
-보안
4. frontController 패턴
web.xml이 모든 servlet, jsp를 매핑하기 힘들다…
그래서 특정 주소(.do)는 frontController가 먼저 나서서 처리한다.
이렇게 가져온 요청들은 frontController가 직접 자원에 접근하도록 다시 요청한다!
(내부에서는 자원에 직접 접근하는 요청이 가능하다.)
5. RequestDispatcher
근데 다시 요청한다는게 어떤 의미인가?
새로운 요청객체를 만드는게 아니라, 처음 만들어진 요청 객체를
다시 내부에서 직접 접근하도록 사용한다는 것!
(이 일을 RequestDispatcher가 한다.)
이렇게 하면 어떤 페이지에서 가져온 데이터를 다른 페이지로 넘어가도 그대로 가져갈 수 있게된다!
6. DispatchServlet
스프링에는 DispatchServlet은 FrontController + RequestDispatcher라고 생각하자.
얘 덕분에 우리는 굳이 frontController와 RequestDispatcher를 구현 안해도 된다.
DipatchServlet이 프로젝트 패키지 내부의 모든 자바 파일을 뒤져서
필요한 객체들(@Controller, @RestController…)을 자동 생성하고,
이 객체들을 IoC로 관리된다.(대부분 필터들이다.)
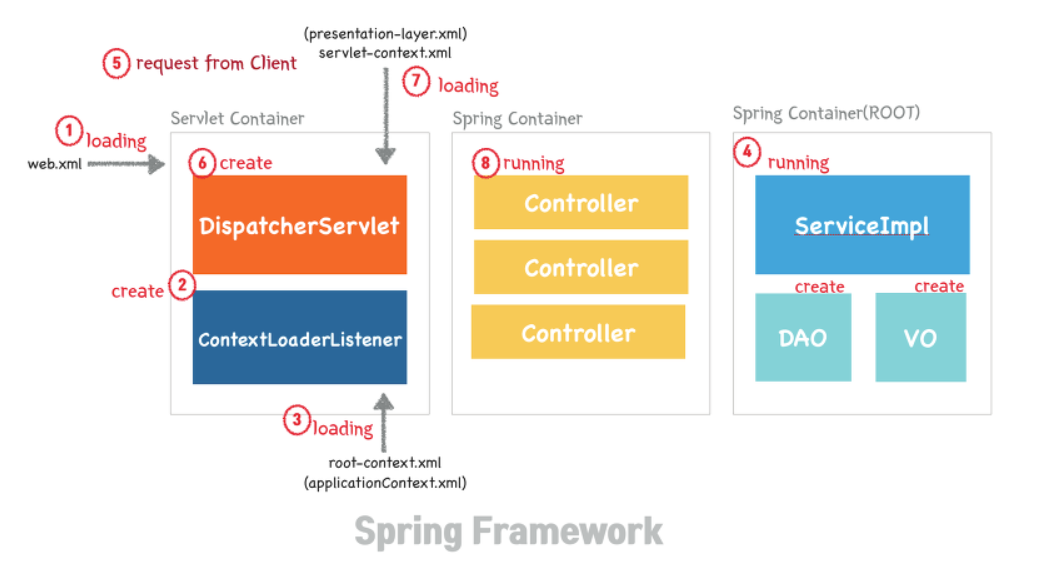
7. 스프링 컨테이너
ApplicationContext
DispatchServlet이 만든 수많은 객체들을 관리하는 애가 스프링 컨테이너다.
이 객체들은 ApplicationContext에 등록되어 관리된다.(IoC)
우리는 new가 아닌 DI로 객체를 다룰 것이다.
ApplicationContext는 두가지가 있다.(root-applicationContext, servlet-applicationContext)
DispatchServlet은 각 스레드 별로 클래스들의 객체들을 만들지만 서로 다른 스레드라서 충돌은 일어나지 않는다.
웹과 관련된 어노테이션을 찾아 메모리에 띄우는 파일인 sevlet-applicationContext이 객체를 생성한다.
다만 DB 같이 쓰레드들이 공유해야 하는 데이터는 ContextLoaderListener이 공유해서 사용하도록 한다.
root-ApplicationContext 파일에 어떤 걸 공유해야 할 지 정해져 있고,
ContextLoaderListener는 이 파일을 읽고, 공유해야 할 내용은 공유한다.
(ContextLoaderListener는 DispatchServlet보다 먼저 실행된다.)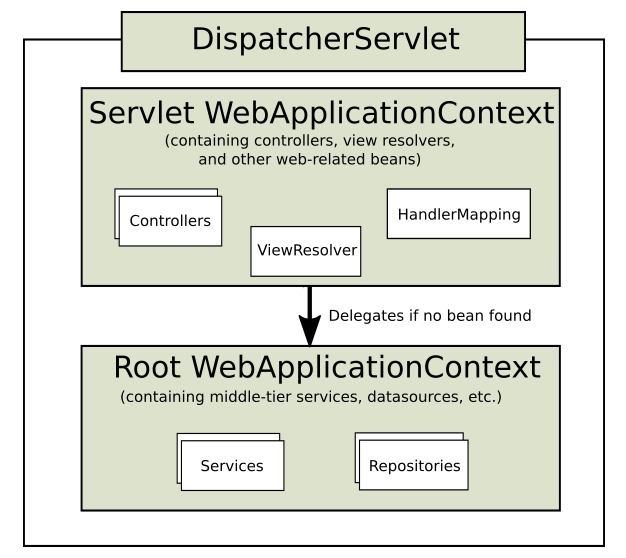
sevlet-applicationContext에서 생성된 객체는 root-applicationContext에서 만들어진 객체를 참조 가능하지만,
반대는 불가능하다~!(생성시점이 다르기 때문이다.)
Bean Factory
Bean Factory도 필요한 객체를 등록해놓은 곳인데, 다만 초기에 메모리에 로드되는게 아니고,
필요할 때 getBean()으로 호출되어야 메모리에 로드된다.(IoC)
ApplicationContext는 초기에 메모리에 로드되는 반면, Bean Factory는 그렇지 않은 lazy loading이다.
8. 응답
- Handler Mapping (요청 주소에 따른 적절한 컨트롤러 요청)
어떤 요청이 오면, 그 요청에 맞는 적절한 컨트롤러의 함수를 찾아 실행한다.
응답할 때는 html로 할 지, data를 응답할 지 결정해야 하는데,
html로 할 때는 ViewResolver가 관여하고(반환값을 jsp파일명으로 인식!),
data로 할 때는 MessageConverter가 작동하게 된다.(기본 컨버팅 값은 json이다.)