파일 시스템
운영체제가 저장매체에 파일을 쓰기 위한 자료구조, 알고리즘
파일 시스템은 왜 만들어졌을까?
비트 단위로 주소를 매겨서 사용하기에는 너무 비효율적!
그렇다고 블록 단위(4kb)로 하자니 사용자가 각 블록의 고유번호로 관리하기 힘듬…
그래서 추상적(논리적) 객체를 도입 : 파일
사용자는 파일 단위로 다루고, 각 파일은 블록 단위로 관리하자!
~
저장매체에 효율적으로 파일 저장하기
가능한 연속적인 공간에 파일을 저장하는 게 좋다.
하지만 각 파일들의 크기가 가변적이라, 불연속 공간에 파일을 저장해야 한다.
- 블록 체인 : 블록을 링크드 리스트로 연결(끝에 있는 블록 찾으려면 처음부터 찾아가야..)
- 인덱스 블록 : 각 블록에 대한 위치 정보를 기록, 한번에 어느 블록이든 찾아갈 수 있음
운영체제 별 파일 시스템
- 윈도우즈 : FAT, FAT32, NTFS
블록 위치를 FAT라는 자료구조에 기록 - 리눅스(UNIX): ext2, ext3, ext4
인덱스 블록 기법인 inode 방식 사용
파일 시스템과 시스템 콜
다양한 파일 시스템 방식에 상관없이 시스템콜을 사용해도 동일한 기능을 활용할 수 있도록 함.
즉 시스템콜을 실행하면, 그 파일 시스템에 맞게 운영체제가 처리한다.
실제로 어떻게 저장하는지는 약간 다를 수 있다.
inode 방식 파일 시스템
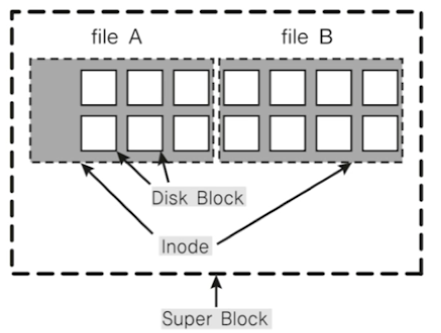
파일 시스템 기본 구조
- 수퍼 블록 : 파일 시스템 정보
- 아이노드 블록 : 파일 상세 정보
- 데이터 블록 : 실제 데이터
파일 : inode 고유값과 자료구조에 의해 주요 정보 관리
- ‘파일이름:inode’로 표현, 파일이름은 inode 번호와 매칭
- 파일 시스템은 inode를 기반으로 파일 엑세스
- inode 기반 메타 데이터 저장
프로세스 생성 - process ID 부여 - PCB에 세부 정보 저장
파일 생성 - inode 번호 부여 - inode 블록에 세부 내용(메타데이터) 저장
이렇게 이해하자.
inode 구조
inode 기반 메타 데이터 : 파일 권한, 소유자 정보, 파일 사이즈, 시간 관련 정보(생성 시간), 데이터 저장 위치 등..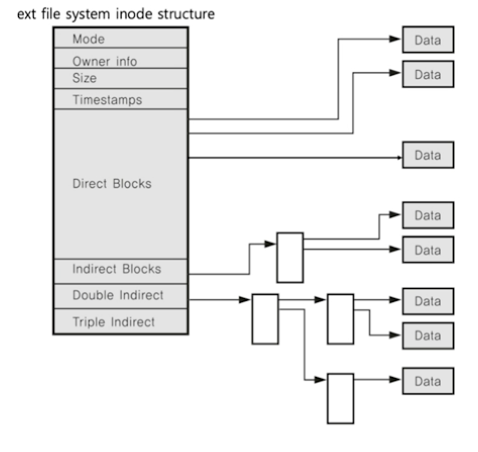
위 사진에서 윗 4칸이 메타 데이터를 담고 있고,
direct blocks에는 실제 데이터가 저장된 주소값 들이 저장되어 있다.
direct blocks에는 대략 12개의 주소값을 저장하고 있는데, 한 블록마다 대략 4kb를 가질 때
direct blocks이 처리할 수 있는 데이터량은 48kb밖에 안된다…
그래서 우리는 single indirect, double indirect, triple indirect를 도입하자.
싱글 - 다이렉트 블록 포인터(1024개)
더블 - 싱글(1024) - 다이렉트(1024 *1 024)
트리플 - 더블(1024) - 싱글(1024 * 1024) - 다이렉트(1024 * 1024 * 1024)
간접 4kb를 갖는데 대략 1024개의 주소를 가질 수 있다.
디렉토리 엔트리(덴트리)
리눅스의 경우..
/home/ubuntu/link.txt 일 때,
- 각 디렉토리 엔트리를 탐색 (각 엔트리는 해당 디렉토리 파일, 디렉토리 정보를 가짐)
맨 앞 슬래시는 루트 디렉토리라 하여, 해당 덴트리에서 home을 찾고 - ubuntu를 찾고 - link.txt를 찾아 실행하는 방식
가상 파일 시스템(Virtual File System)
다른 파일 시스템이더라도 같은 시스템콜을 써도 잘 돌아가게 하는 시스템
다양한 기기에도 파일 시스템 인터페이스를 통해 관리 가능하게 됨