컬렉터란 무엇인가?
일단 예시를 하나 보자.
1 | //통화별로 트랜잭션을 그룹화한 코드(명령형 버전) |
딱봐도 함수형 프로그래밍이 훨씬 쉽다.
위 예제에서 collect 메서드로 Collector 인터페이스 구현을 전달했다.
Collector 인터페이스 구현은 스트림의 요소를 어떤 식으로 도출할지 지정한다.
컬렉터는 고급 리듀싱 기능을 수행한다.
스트림에 collect를 호출하면, 스트림의 요소에 (컬렉터로 파라미터화된) 리듀싱 연산이 수행된다.
collect에서는 리듀싱 연산을 이용해서 스트림의 각 요소를 방문하면서 컬렉터가 작업을 처리한다.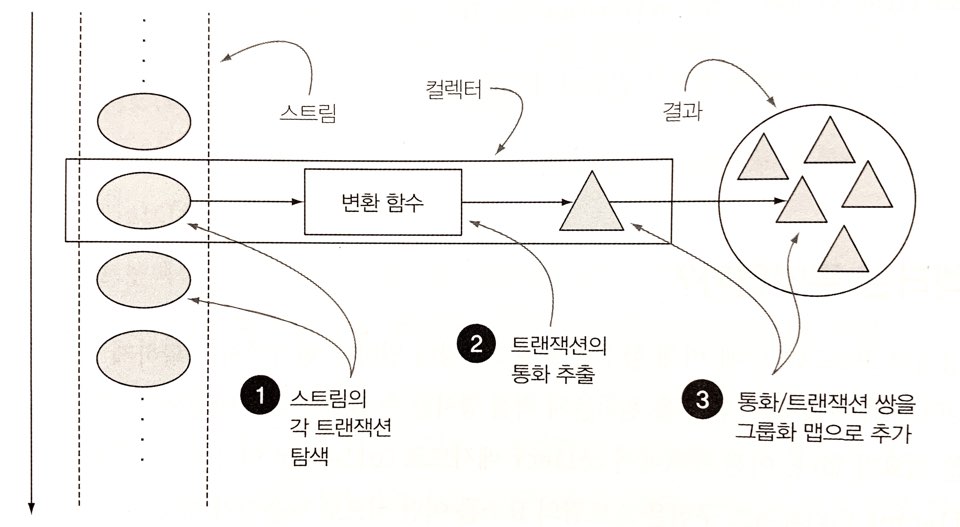
미리 정의된 컬렉터
Collectors 클래스에서 미리 정의된 팩터리 메서드의 기능은 크게 세가지로 분류된다.
- 스트림 요소를 하나의 값으로 리듀스하고 요약.
- 요소 그룹화
- 요소 분할
이 세가지에 대해 더 알아보자.
리듀싱과 요약
컬렉터로 스트림의 모든 항목을 하나의 결과로 합칠 수 있었다.
하나의 결과란 복잡한 다수준 그룹화 맵 일 수도, 그냥 평범한 정수 형태 일 수도 있다.
counting()이란 팩토리 메서드가 반환하는 컬렉터로 메뉴에서 요리 수를 계산해보자
1 | long howManyDishes = menu.stream().collect(Collectors.counting()); |
요약 연산
스트림에 있는 객체의 숫자 필드의 합계나 평균 등을 반환하는 연산을 요약 연산이라 부른다.
물론 요약 연산에도 리듀싱 기능이 자주 사용된다.
Collectors 클래스는 Collectors.summingInt라는 요약 팩토리 메서드를 제공한다.
summingInt 인수로 전달된 함수는 객체를 int로 매핑하는 함수를 인수로 받는다.
int로 매핑한 컬렉터를 collet 메서드에 전달되면, 요약 작업을 수행한다.
1 | int totalCalories = menu.stream().collect(summingInt(Dish::getCalories)); |
이런 역할은 summingInt 뿐만 아니라,summingLong, summingDouble 등이 있다.
합계를 구하는 과정 말고, 평균을 구하는 averagingInt도 가능하다
두 개 이상의 연산을 해야 되면..?
summarizingInt가 반환하는 내용을 사용하면 된다!
하나의 요약 연산으로 여러가지 연산값을 얻을 수 있다!
1 | IntSummaryStatics menuStatistics = menu.stream().collect(summarizingInt(Dish::getCalories)); |
문자열 연결
컬렉터에 joining 팩터리 메서드를 사용하면 스트림의 각 객체에 toString 메서드를 호출해서 추출한 모든 문자열을 하나의 문자열로 만든다.
joining 메서는 내부적으로 StringBuilder를 이용해 문자열을 하나로 만든다.
1 | String shortMenu = menu.stream().map(Dish::getName).collect(joining()); |
collect와 reduce의 차이?
둘 다 비슷한 결과를 만들 수 있어서 어떤 것을 사용해야하는지 헷갈린다.
collect 메서드는 결과를 누적하는 컨테이너로 바꾸도록 설계된 메서드이고,
reduce는 두 값을 하나로 도출하는 불변형 연산이다!
그룹화
분류 함수인 groupingBy 메서드를 활용해보자.
1 | Map<Dish.Type, List<Dish>> dishesByType = |
Dish 클래스의 Type을 키로 키에 맞는 스트림 요소들을 map에 담아 반환했다.
하지만 여러 가지 기준으로 그룹화하려면 어떨까..?
그룹화된 요소 조작
고기, 생선, 그 외 음식들로 분류하고, 500칼로리가 넘는 음식을 얻으려면 어떻게 해야 할까?
1 | Map<Dish, Type, List<Dish>> caloricDishesByType = |
이 방식에는 치명적인 문제가 있다. 만약 생선류에 500칼로리가 넘는 음식이 없으면 아예 그 키를 없앤다는거다.
출력하면 {OTHER=[french fries, pizza], MEAT=[pork, beef]}가 출력된다.
groupingBy는 두번째 인수로 Collector를 가질 수 있도록 만들어 이를 해결한다.
두번째 Collector 안에 필터 프레디케이트를 넣으면 된다.
Collectors의 정적 팩토리 메서드 filtering메소드는 프레디케이트를 인수로 받아 리스트로 만든다.
1 | Map<Dish.Type, List<Dish>> caloricDishesByType = |
mapping메소드 사용 예시도 보자
1 | Map<Dish.Type, List<String>> dishNameByType = |
이러면 이름을 기반으로 한 맵이 반환될 것이다.
flatmapping메소드 사용 예시도 보자
dishTags가 음식이름, 관련 문자열 리스트로 매핑된 맵이라고 했을 때,
1 | Map<Dish.Type, Set<String>> dishNamesByType = |
groupingBy 여러개를 연결해서 다수준 그룹화
1 | Map<Dish.Type, Map<Caloriclevel, List<Dish>>> dishesByTypeCaloricLevel = |
- 종류로 그룹화
- 칼로리로 DIET, NORMAL, FAT으로 그룹화
이 과정을 버킷 개념으로 생각하면 편한다. 첫 그룹화로 한 버킷에 육류 음식들이 담기고, 그 버킷을 또 칼로리별로 여러 버킷으로 나눠 담았다!
분할
분할은 프레디케이트를 분류 함수로 사용하는 특수한 그룹화 기능.
이런 분류 함수는 분할 함수라고 하는데, 분할 함수는 불리언을 반환하므로 맵의 키 형식은 Boolean이다.
즉 분할 그룹화는 최대 두 개 그룹으로 나뉜다.
1 | Map<Boolean, List<Dish>> partitionedMenu = |
분할은 참 거짓 두가지 요소 스트림 리스트를 모두 유지한다는 장점이 있다.
1 | Map<Boolean, Map<Dish.Type, List<Dish>>> vegetarianDishesByType = menu.stream(). |